
Table of Contents
- Arabic Linguistic Structure Challenges in Artificial Intelligence
- Arabic Dialects and Multi-Context Challenges
- Right-to-Left (RTL) Writing Challenges in AI Systems
- The Arabic Data Gap and Data Quality Challenges
- Semantic and Contextual Understanding Challenges in Arabic AI
- Integration and Deployment Challenges for Arabic AI Models
- How Does Widebot Provide Practical Solutions to These Challenges?
- Conclusion: The Future of Arabic in the AI Era
Arabic Language Challenges in Artificial Intelligence 2026: From Linguistic Structure to Dialects and RTL
Complex linguistic structures, diverse Arabic dialects, right-to-left (RTL) writing, limited high-quality data, and deep contextual ambiguity, these are not marginal issues. They represent the most critical Arabic language challenges in artificial intelligence by 2026, challenges that will ultimately determine which organizations succeed and which fall behind in the digital transformation race across the Arab world.
As artificial intelligence continues to advance at an unprecedented pace and expand rapidly across governments and large enterprises, Arabic stands out as a uniquely complex language,one that requires purpose-built AI models, not generalized, imported solutions.
In this article, we provide an in-depth, analytical overview of the key Arabic language challenges in AI for 2026, their direct impact on organizations, and the practical solutions delivered by Widebot through its AQL GenAI model.
bic speakers globally, Arabic data used for training AI models remains:
- Significantly smaller in volume compared to English
- Less diverse across dialects and domains
- Inconsistent in quality

Here are the key challenges of the Arabic language in artificial intelligence in 2026:
1. Arabic Linguistic Structure Challenges in Artificial Intelligence
Arabic linguistic structure is among the most complex areas in natural language processing. A single Arabic word may contain a root, pattern, prefixes, suffixes, and attached pronouns, making automated analysis significantly more difficult than in most Indo-European languages.
Arabic is fundamentally a root-based derivational language, where a trilateral or quadrilateral root can generate thousands of word forms.
For example, a single triliteral root can generate multiple related forms through subtle morphological variations; each altering the word’s meaning, grammatical function, and contextual usage.
This structural complexity reduces the accuracy of global AI models by 25–35% in tasks such as:
- Named Entity Recognition (NER)
- Part-of-Speech (POS) tagging
The problem is further compounded by the absence of diacritics in most digital Arabic text. Without diacritics, a single word can carry multiple grammatical and semantic interpretations, directly impacting the accuracy of intent classification, entity extraction, and text generation systems.
2. Arabic Dialects and Multi-Context Challenges
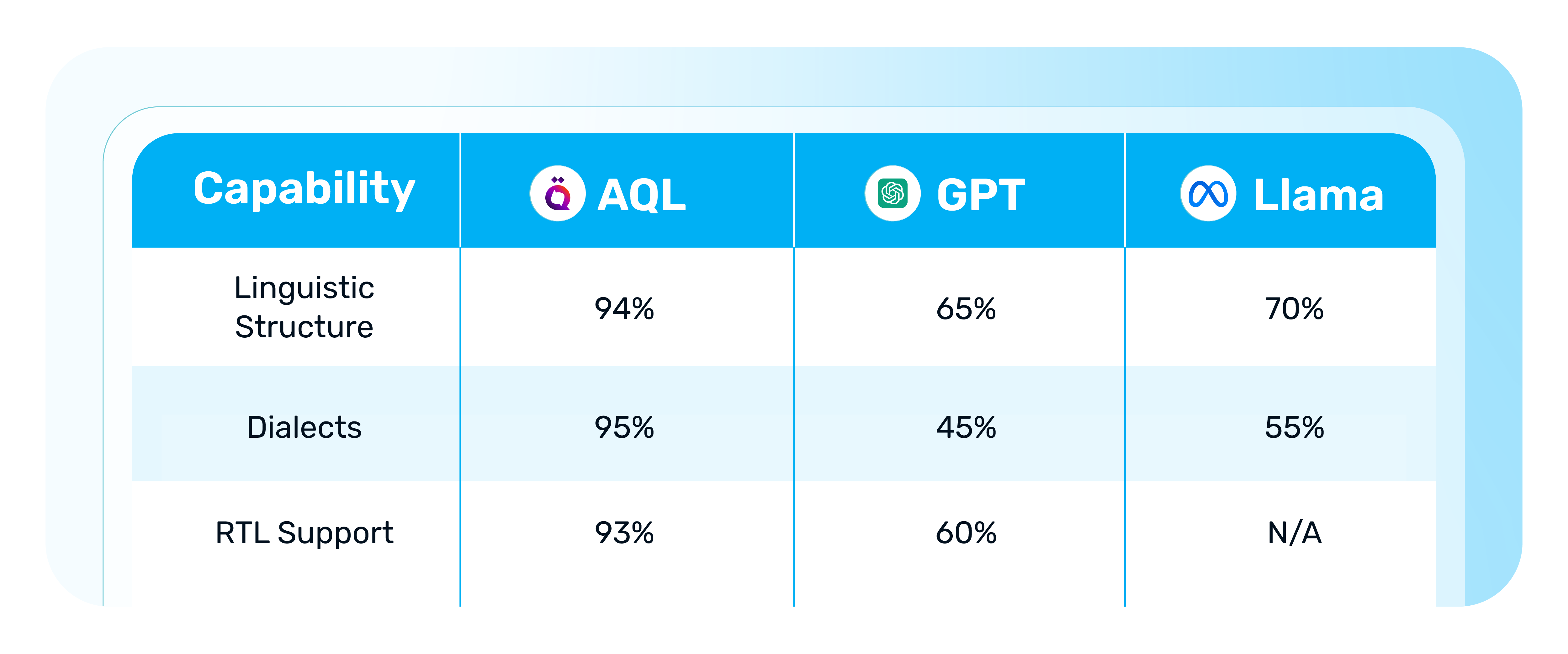
Arabic consists of more than 30 major dialect groups, with variations of 60–80% in pronunciation, vocabulary, and structure. While global models such as GPT-4 perform relatively well in Modern Standard Arabic (approximately 85% accuracy), their performance drops sharply-to 45% or less-when handling dialectal Arabic.
Today, over two-thirds of Arabic digital content is written in local dialects rather than Modern Standard Arabic. These dialects differ significantly in:
- Vocabulary
- Grammatical structure
- Cultural and contextual meaning
General-purpose AI models frequently fail to distinguish between dialects or interpret them accurately, leading to unnatural responses, misunderstandings, and incorrect outputs, particularly in conversational AI and customer service applications.
💡 To address this, Widebot delivers Speech-to-Text (STT) and Text-to-Speech (TTS) through its AQL AI model, supporting over 25 Arabic dialects with 95% Word Error Rate (WER) accuracy, while reducing wait times by more than 70% across multiple industries.
Discover more about WideBot’s technologies and products.
3. Right-to-Left (RTL) Writing Challenges
The Arabic language differs not only linguistically, but technically as well.
Right-to-left (RTL) writing presents a major challenge when it comes to:
- Integrating Arabic text with numbers or left-to-right languages
- Analyzing textual data
- Displaying content within user interfaces and analytical reports
These challenges frequently lead to errors in OCR and TTS systems. In government applications in particular, they hinder the accurate processing of PDFs and scanned document images. Any weakness in RTL handling directly and negatively impacts user experience, data integrity, and analytical accuracy.
4. The Arabic Data Gap and Quality Challenges
Despite the large number of Arabic speakers globally, Arabic data used for training AI models remains:
- Significantly smaller in volume compared to English
- Less diverse across dialects and domains
- Inconsistent in quality

101 billion words (Arabic Words Dataset)
116 billion tokens (AraC4)
Moreover, 80–95% of this data focuses on Modern Standard Arabic, while dialectal content accounts for less than 10%, leading to significant bias and hallucinations when models process real-world dialectal input.This imbalance poses a direct challenge to training large language models capable of understanding and generating Arabic with high accuracy.
5. Semantic and Contextual Understanding Challenges
Arabic relies heavily on context, rhetoric, and implicit meaning. As a result, tasks such as sentiment analysis and intent detection become significantly more complex—especially in short texts or dialectal expressions.
Without deep contextual understanding, AI systems are prone to misinterpretation and flawed automated decisions, a risk that becomes critical in sensitive sectors such as government services, finance, and healthcare.
6. Integration and Deployment Challenges for Arabic AI Models
For governments and large enterprises, the challenge extends beyond model accuracy to include:
- Deployment strategy (on-premise, cloud, or hybrid)
- Compliance with local regulations
- Protection of sensitive data
Many institutions reject AI models hosted outside national borders due to privacy and security concerns. This creates a strong need for flexible, compliant, and secure deployment architectures tailored to local requirements.
How Does Widebot Provide Practical Solutions?
Widebot treats Arabic as the foundation, not an afterthought. Through AQL GenAI, Widebot delivers purpose-built solutions including:
Widebot treats Arabic as the foundation; not an afterthought.
Through AQL GenAI, Widebot delivers purpose-built solutions that include:
- Arabic-native Large Language Models (LLMs)
- Advanced dialect understanding and generation
- Architecture designed specifically for RTL processing
- Industry- and domain-customizable models
- On-premise, cloud, and hybrid deployment options aligned with government requirements
Conclusion: The Future of Arabic in the AI Era
By 2026, Arabic is no longer a peripheral challenge in artificial intelligence. It has become a decisive benchmark for measuring the maturity of intelligent systems and their ability to operate in real-world, high-complexity environments.
Superficial Arabic support is no longer sufficient for governments and enterprises seeking accuracy, reliability, regulatory compliance, and human-like user experiences.
Through AQL GenAI, Widebot demonstrates that Arabic linguistic challenges—ranging from morphology and dialect diversity to RTL and data privacy—can be transformed into a genuine competitive advantage. Deep Arabic understanding is no longer a technical burden, but a strategic opportunity to build AI systems that are culturally aligned, user-centric, and operationally scalable.
Whether you are a government entity modernizing digital services, an enterprise automating customer engagement, or a developer seeking trusted Arabic AI models, investing in AI built for Arabic from the ground up is the smartest path forward.
Start building intelligent systems that speak Arabic the way humans do.
Book a meeting with the Widebot team today!





%20(1).webp)

