.jpg)
أولًا: ما هي النماذج اللغوية الكبيرة
LLMs؟الدليل الكامل لصنّاع القرار في الحكومات والمؤسسات الكبرى
تخيّل لو كان لديك موظف خارق يستطيع قراءة ملايين الصفحات في دقائق، تلخيصها لك في سطور قليلة، والرد على أسئلة عملائك أو مواطنيك بلغة طبيعية وكأنه إنسان.
هذا الموظف لم يعد خيالًا علميًا، بل أصبح حقيقة مع نماذج اللغة الكبيرة (LLMs).
هذه النماذج هي العمود الفقري للثورة الحالية في الذكاء الاصطناعي، والسر وراء قدرتها على إعادة تشكيل طريقة عمل المؤسسات — من خدمة العملاء الحكومية، إلى كشف الاحتيال في البنوك، مرورًا بمعالجة المطالبات التأمينية.
اليوم، صانعي القرار أمام لحظة فاصلة: إما الاستفادة من هذه التكنولوجيا لتسريع التحول الرقمي، أو ترك المنافسين يتقدّمون خطوة بخطوة.
وحسب تقرير McKinsey، يمكن للذكاء التوليدي أن يضيف ما بين 2.6 إلى 4.4 تريليون دولار سنويًا للاقتصاد العالمي، رقم يعكس حجم التأثير المتوقع.
ما هي نماذج اللغة الكبيرة (LLM)؟
نماذج اللغة الكبيرة هي أنظمة ذكاء اصطناعي تُبنى على التعلّم العميق، وتُدرّب على مليارات الكلمات والجمل من الإنترنت والكتب والمستندات. الهدف منها: فهم الأنماط اللغوية وتوليد نصوص طبيعية وواقعية.
لماذا “كبيرة”؟
لأنها تحتوي على مليارات أو حتى تريليونات من المعاملات (Parameters). مثلًا: GPT-3 لديه 175 مليار معامل، وGPT-4 يقدَّر بتريليونات.
خلفية تاريخية
- قبل 2017: كانت النماذج تعتمد على شبكات عصبية متكررة (RNNs, LSTMs) تقرأ النصوص كلمة وراء كلمة. النتيجة: بطيئة جدًا وصعبة التدريب.
- 2017 – بحث "Attention is All You Need":
هنا ظهرت قفزة ثورية. الباحثون في جوجل قدّموا نموذج جديد اسمه Transformer. فكرته الأساسية: بدل ما النموذج يقرأ كل كلمة بالترتيب، بيستخدم آلية اسمها الانتباه (Attention Mechanism).
الانتباه باختصار: يسمح للنموذج يركّز على الكلمات الأكثر ارتباطًا بالمعنى في النص.
- مثال: في جملة "المواطن قدّم شكوى بسبب رسوم التحويل" → النموذج يفهم أن كلمة "رسوم" مرتبطة بـ "التحويل" أكتر من "المواطن".
- مثال: في جملة "المواطن قدّم شكوى بسبب رسوم التحويل" → النموذج يفهم أن كلمة "رسوم" مرتبطة بـ "التحويل" أكتر من "المواطن".
- النتيجة:
- سرعة تدريب أعلى.
- فهم أعمق للسياق.
- إمكانية بناء نماذج ضخمة جدًا مثل GPT وBERT وLLAMA.
- سرعة تدريب أعلى.
- 2018 – BERT: أول نموذج مبني على Transformers من جوجل، غيّر أبحاث معالجة اللغة الطبيعية.
- 2020 – GPT-3: فتح الباب أمام التوليد الطبيعي للنصوص.
- 2022 – ChatGPT: جعل الـLLM جزءًا من حياة ملايين المستخدمين.
- اليوم: مؤسسات كبرى تطور نماذجها الخاصة أو تعتمد على حلول مخصصة مثل LLM عقل من وايدبوت.
القدرات الأساسية
- توليد نصوص طبيعية.
- تلخيص مستندات طويلة.
- ترجمة لغات متعددة.
- تحليل المشاعر.
- دعم عمليات صنع القرار.
كيف يعمل LLM؟
وراء كل إجابة “ذكية” يولّدها نموذج اللغة الكبير، في رحلة معقّدة تبدأ من ملايين الصفحات وتنتهي بكلمات واضحة على شاشتك. خلينا نشرح المراحل الأساسية:
1. التدريب المسبق (Pre-training)
- يتم تدريب النموذج على مليارات النصوص المأخوذة من الكتب، المقالات، المواقع الإلكترونية، وأحيانًا حتى المحادثات.
- الفكرة الأساسية: النموذج يتعلم التنبؤ بالكلمة التالية في أي جملة.
- مع تكرار العملية تريليونات المرات، يبدأ النموذج يكوّن خريطة لغوية للعالم: كيف تُستخدم الكلمات، ما علاقتها ببعضها، وكيف يتغير المعنى باختلاف السياق.
- النتيجة: قاعدة معرفية عامة تُشبه “ذاكرة بشرية ضخمة” لكنها متكوّنة من أنماط إحصائية.
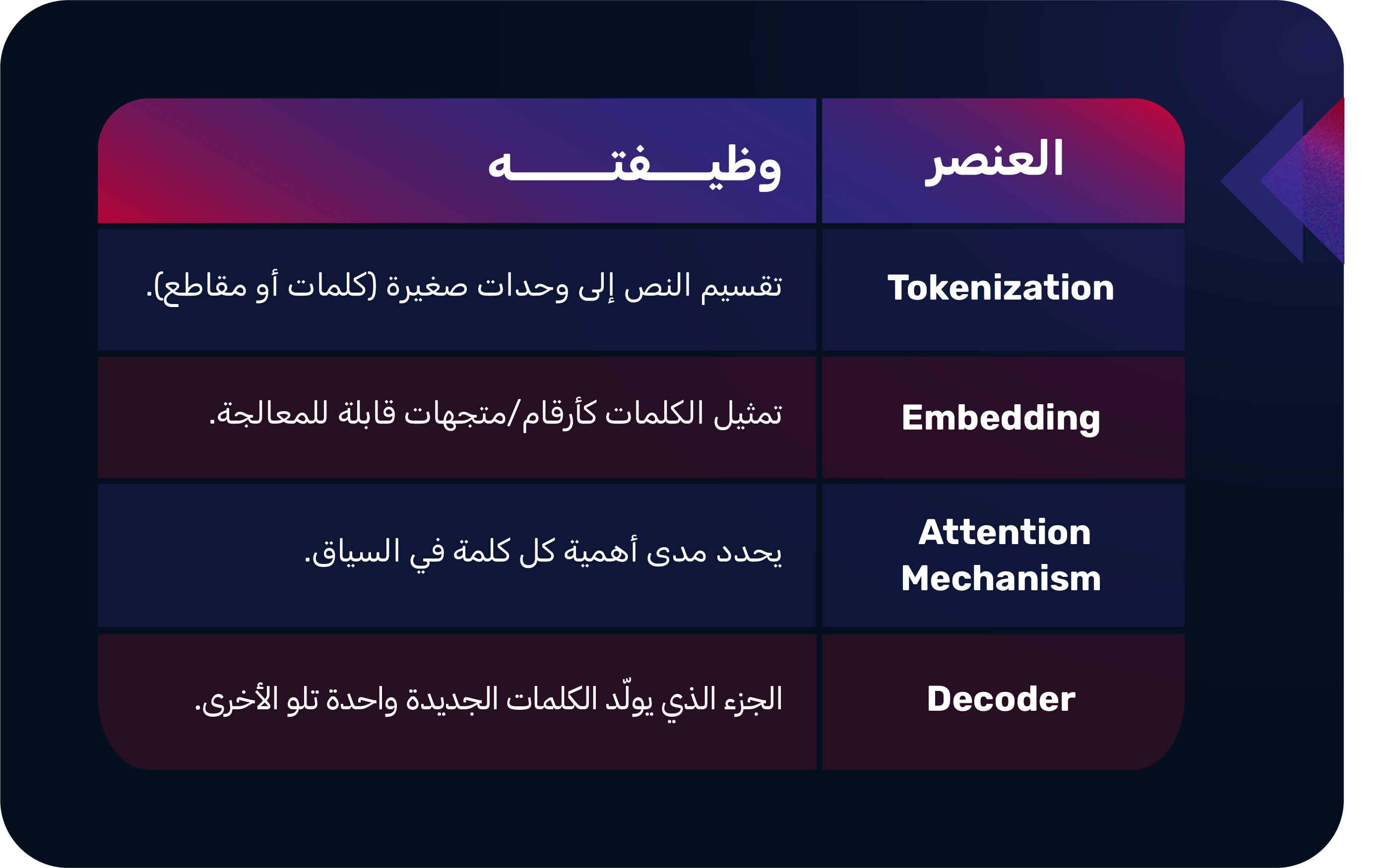
2. التقسيم إلى وحدات (Tokenization)
- النموذج لا يفهم اللغة كجُمل كاملة.
- بدل ذلك، يُحوَّل النص إلى Tokens (وحدات أصغر).
- مثلًا: كلمة “الذكاء” قد تنقسم إلى جزأين (ذكا + ء).
- مثلًا: كلمة “الذكاء” قد تنقسم إلى جزأين (ذكا + ء).
- كل Token يُحوَّل إلى متجه رياضي (Vector) — أرقام تمثّل المعنى.
- هذه المتجهات تدخل في الشبكة العصبية لتُعالج وتتحوّل لاحقًا إلى كلمات مفهومة.
3. آلية الانتباه (Attention Mechanism)
هنا يكمن السر الحقيقي وراء قوة الـLLM.
الانتباه يسمح للنموذج أن يُقرّر أي الكلمات أهم في الجملة لفهم المعنى.
🔹 مثال من الحكومة:
في جملة “المواطن قدّم طلبًا عاجلًا للحصول على تجديد جواز السفر” → النموذج يفهم أن كلمة “عاجلًا” مرتبطة أكثر بـ “طلب” و*“تجديد جواز السفر”*، وليست مرتبطة بكلمة “المواطن”.
🔹 مثال من البنوك:
في جملة “العميل اعترض على خصم غير مبرر في كشف الحساب” → النموذج يدرك أن كلمة “غير مبرر” مرتبطة بـ “الخصم”، وليس بـ “العميل”.
🔹 مثال من التأمين:
في جملة “العميل أرسل مطالبة بسبب حادث السيارة الأخير” → النموذج يربط كلمة “حادث” بـ “السيارة”، وليس بالعميل نفسه.
بهذا الشكل، النموذج يركّز على المعنى الصحيح، مما يجعله قادرًا على فهم السياق الحقيقي للجملة.
هذه الآلية تجعل النماذج الحديثة (Transformers) أكثر دقة وذكاء من النماذج القديمة (RNNs) التي كانت تعالج النصوص بشكل خطي من البداية للنهاية دون تمييز الكلمات الأكثر أهمية.
4. الضبط الدقيق (Fine-tuning)
- بعد التدريب المسبق، النموذج لا يزال عامًا جدًا.
- هنا يأتي دور الضبط الدقيق: إعادة تدريبه على بيانات خاصة بمجال المؤسسة (قوانين حكومية، عقود مصرفية، مطالبات تأمين).
- هذا يحوّل النموذج من “عارف باللغة” إلى “خبير متخصص” يخدم قطاعك مباشرة.
5. التعلّم من التغذية الراجعة البشرية (RLHF – Reinforcement Learning with Human Feedback)
- البشر يقيّمون مخرجات النموذج: أي إجابة جيدة وأيها ضعيفة.
- النموذج يتعلم من هذه التقييمات ليصبح أكثر دقة وأقرب لأسلوب البشر.
- مثلًا: لو أعطى إجابة صحيحة لكنها جافة جدًا، قد يُعاد توجيهه ليكتب بنفس الأسلوب لكن بشكل أكثر وضوحًا وإنسانية.
6. توليد الإجابة (Inference)
- عند طرح سؤال جديد، يمر عبر المراحل التالية:
- يتحوّل إلى Tokens → Vectors.
- تمر المتجهات عبر طبقات Attention لتُفهم معانيها.
- يُولّد النموذج Tokens جديدة تمثل الإجابة.
- تتحوّل الـTokens إلى كلمات وجمل تُعرض للمستخدم.
- يتحوّل إلى Tokens → Vectors.
- النتيجة: إجابة تبدو “بشرية”، لكنها مبنية على إحصائيات دقيقة للغة.
الملخص:
نماذج اللغة الكبيرة تشبه “عقل لغوي ضخم” يتعلم من النصوص، يفككها إلى رياضيات، ويركّبها مرة أخرى كجُمل جديدة. قوتها تأتي من مزيج التدريب الهائل + آلية الانتباه + التخصيص، وهو ما جعلها نقطة تحول في الذكاء الاصطناعي الحديث.
📌 دراسة arXiv تشير إلى أن تقنيات LLM يمكن أن تؤثر على المهام التي يؤديها نحو 80٪ من القوى العاملة عالميًا، مما يجعل فهم كيفية عملها ضرورة استراتيجية لكل مؤسسة.
ثالثًا: مكونات النموذج تقنيًا
- تعتمد معظم LLMs على بنية "المحوّلات" أو Transformers، التي قدمتها Google في 2017.
- هذه البنية تسمح للنموذج بفهم السياق الكامل للنص، وليس فقط الكلمات المجاورة.
عناصر رئيسية:
الفرق بين LLM وRAG
- LLM فقط: يعتمد على المعرفة حتى تاريخ تدريبه (Knowledge Cutoff).
- LLM + RAG: يربط النموذج ببيانات حقيقية من المؤسسة لتوليد إجابات دقيقة وحديثة.
➡️ [اقرأ دليل RAG الكامل من وايدبوت ](رابط مقال RAG).
رابعًا: أحدث النماذج اللغوية الكبيرة (2025 - 2026)
1. GPT-4o (من OpenAI)
- الإصدار الأحدث من سلسلة GPT.
- يتميز بالسرعة، دعم النص والصوت والصورة في وقت واحد (نموذج متعدد الوسائط).
- متوفر في ChatGPT المجاني والمدفوع.
2. Claude 3 (من Anthropic)
- يُعرف بقدرته العالية على الفهم والسياق العميق، وخاصة في القراءة التحليلية.
- Claude 3 Opus هو الأعلى أداءً ضمن السلسلة.
3. Gemini 1.5 (من Google DeepMind)
- يتميز بذاكرة طويلة الأمد، مما يسمح له بتذكر معلومات كثيرة من جلسة واحدة.
- مدمج في منتجات Google مثل Docs وSearch.
4. AQL (من شركة WideBot AI)
- مغلق المصدر، خفيف وسريع.
- مناسب للأنظمة والمؤسسات العربية التي تتواصل مع العملاء بعدة لهجات عربية.
5. Llama 3 (من Meta)
- مفتوح المصدر.
- LLaMA 3-70B من أقوى النماذج المجانية المتاحة حاليًا.
أمثلة عملية على استخدام LLMs

المزايا الرئيسية
- تحسين تجربة العملاء.
- تقليل التكاليف (تكلفة تشغيل LLM انخفضت بأكثر من 80٪ سنويًا وفق McKinsey).
- أتمتة العمليات الروتينية.
التحديات
- الهلاوس (Hallucinations): إجابات واثقة لكنها خاطئة.
- المعلومات القديمة: بسبب الـ Knowledge Cutoff.
- الخصوصية: إدخال بيانات حساسة في نموذج عام مخاطرة.
- اللغة: معظم النماذج العالمية لا تفهم اللهجات العربية بدقة.
📌 وفقًا لتقرير Deloitte، 82٪ من شركات التأمين تخطط لاستخدام الذكاء الاصطناعي خلال السنوات الثلاث القادمة — لكن فجوة الجاهزية تظل تحديًا أساسيًا.
أفضل الممارسات
- اختيار نموذج مخصص للغة والسياق (مثل وايدبوت عقل).
- دمج LLM مع RAG لتقليل الأخطاء.
- إستضافة محلية لضمان الأمان.
- تدريب الموظفين على التدخل البشري عند الحاجة.
- تحديث البيانات باستمرار.
وايدبوت و LLM عقل
- LLM عقل: أول نموذج لغوي عربي بدقة عالية يدعم أكثر من 25 لهجة.
- إستضافة محلية: توافق مع القوانين الوطنية.
- تكامل سلس: مع ERP, CRM وأنظمة حكومية أو مصرفية.
- تحليلات متقدمة: لدعم متخذي القرار.
➡️ [تعرّف على LLM عقل من وايدبوت](من هنا).
وايدبوت و LLM عقل
- LLM عقل: أول نموذج لغوي عربي بدقة عالية يدعم أكثر من 25 لهجة.
- إستضافة محلية: توافق مع القوانين الوطنية.
- تكامل سلس: مع ERP, CRM وأنظمة حكومية أو مصرفية.
- تحليلات متقدمة: لدعم متخذي القرار.
➡️ [تعرّف على LLM عقل من وايدبوت](من هنا).
كيف تبدأ مع LLM في مؤسستك؟
- تقييم الاحتياج.
- تجهيز البيانات.
- اختيار الشريك التقني (وايدبوت).
- إطلاق مشروع تجريبي (Pilot).
- التوسع التدريجي.
👉 [احجز اجتماع مع فريق المبيعات](رابط حجز اجتماع) لنضع خطة مخصصة تناسب احتياجاتك.
في النهاية، المؤسسات العظيمة لا تُقاس فقط بما تُقدمه اليوم، بل بقدرتها على الاستعداد لغدٍ أكثر تعقيدًا.
نماذج اللغة الكبيرة (LLMs) لم تعد رفاهية تقنية أو اتجاهًا عابرًا، بل أصبحت لغة المستقبل التي سيُقاس بها مستوى كفاءة الحكومات، وابتكار البنوك، ومرونة شركات التأمين.
القرار اليوم ليس عن “تبنّي تقنية جديدة”، بل عن تأمين موقعك في سباق المنافسة. فإما أن تختار المبادرة، أو تترك المجال مفتوحًا لغيرك ليتفوق.
ومع وايدبوت، يمكنك أن تبدأ هذه الرحلة بثقة:
- نموذج عقل العربي الذي يفهمك ويفهم عملائك.
- إستضافة محلية تحافظ على خصوصيتك.
- حلول مرنة تنمو معك، وتتكامل مع أنظمتك القائمة.
🚀 لا تنتظر اللحظة المثالية… اصنعها بنفسك:
- [تعرّف على LLM عقل من وايدبوت] (من هنا).
[احجز اجتماعًا مع فريق المبيعات اليوم] (رابط حجز اجتماع)




