.jpg)
في عصر تتسارع فيه تقنيات الذكاء الاصطناعي والاتجاه نحو الاعتماد عليها في مهام خطيرة من منها قرارات الحكومات واستراتيجيات الشركات الكبرى، تبرز ظاهرة هلوسة الذكاء الاصطناعي كأحد أكبر التحديات الخفية التي يمكنها تغيير قواعد اللعبة.
هذا المقال يكشف لك ما هي هلوسة الذكاء الاصطناعي، وما هي أسبابه، والأنواع، والمخاطر الحقيقية لهذه الظاهرة، ويقدّم طُرقًا عملية للوقاية منها، إلى جانب مقارنة بين النماذج المختلفة — ليكون دليل الحكومات والشركات لفهم وتوظيف الذكاء الاصطناعي بثقة ووعي.
ما هي هلوسة الذكاء الاصطناعي AI hallucination؟
هلوسة الذكاء الاصطناعي (AI hallucination) هي ظاهرة تحدث عندما يقوم نموذج الذكاء الاصطناعي، خاصة النماذج اللغوية الكبيرة مثل ChatGPT، بإنتاج معلومات خاطئة أو غير دقيقة أو حتى مخُتلقة بالكامل، ويعرضها وكأنها صحيحة وتبدو مقنعة ومنطقية.
هذه واحدة من أبرز تحديات نماذج اللغة الكبيرة LLMs، خاصة عند استخدامها في مجالات تتطلب دقة وموثوقية عالية.
سُمّيت هذه الظاهرة باسم هلوسة الذكاء الاصطناعي قياسًا على ظاهرة الهلوسة في علم النفس البشري، وهي الحالة التي يحدث فيها تغير في الوعي ما ينجم عنه إدراك غير حقيقي وغير موجود في الواقع.
يحدث نفس الشيء لنماذج الذكاء الاصطناعي حيث ترد في حالة هلوستها برُدود وأجوبة مؤكدة قد يشعر معها المحاور أنها صحيحة لكنها في الواقع ليست كذلك. كما أن هذه البيانات أو المعلومات لا وجود لها وليست ضمن البيانات التي تم تدريب النموذج عليها.
لماذا تحدث هلوسة الذكاء الاصطناعي؟
تحدث "الهلوسة" لأن نماذج الذكاء الاصطناعي لا تفهم الحقيقة كما يفهمها الإنسان، بل تعتمد على أنماط اللغة والإحصاءات. لذلك قد تولد مخرجات "منطقية ظاهريًا" لكنها غير دقيقة أو مخترعة. وهناك أسباب متعددة تؤدي إلى هلوسة الذكاء الاصطناعي تتعلق بكيفية عمل وتدريب نماذج الذكاء الاصطناعي، إليك أبرز هذه الأسباب:
1. طبيعة التدريب على البيانات
نماذج الذكاء الاصطناعي الكبيرة، مثل GPT، تُدرَّب على كميات ضخمة جدًا من البيانات النصية التي تشمل كُتبًا، مقالات، صفحات إنترنت، منتديات، شبكات اجتماعية، وغيرها. هذه البيانات لا تمر دائمًا بمرحلة "تنقية" للتحقق من صحة المعلومات، بل يتم جمعها لتغطية أكبر قدر ممكن من اللغة والمعاني والسياقات.
⚠️المشكلة: إذا كانت البيانات تحتوي على معلومات خاطئة أو شائعات منتشرة أو تحيزات، فإن النموذج يتعلم هذه المعلومات كما هي، دون أن يكون لديه آلية لتمييز الصحيح من الخاطئ. النموذج لا يملك مفهوماً للحقيقة، بل "يتعلم التكرار".
💡مثال: قد يكرر النموذج المعلومة الشائعة والخاطئة بأن "الإنسان يستخدم 10% فقط من دماغه"، لأنها وردت مرارًا في الأفلام أو المواقع، رغم أنها غير صحيحة علميًا.
2. غياب المعرفة الفعلية أو التحقق الفوري
النموذج لا يرتبط افتراضيًا بقاعدة بيانات حية أو بمحركات بحث، ما لم يتم دمجه بأدوات مثل Bing أو Google. وبالتالي، لا يستطيع الوصول إلى المعلومات الحديثة أو المحدثة بعد تاريخ تدريبه، ولا يمكنه "التحقق" من أي معلومة بشكل مباشر أثناء المحادثة.
⚠️المشكلة: إذا طُلب منه رقم دقيق، أو اسم تقرير حديث، أو حدث جارٍ، فقد يقوم بتوليد إجابة "تخمينية" لا تستند إلى مصدر حقيقي، بل إلى السياقات اللغوية التي تدرب عليها.
💡مثال: إذا سألته: كم عدد الشركات الناشئة في السعودية في 2025؟، فقد يجيب: هناك 4600 شركة ناشئة، رغم أن هذا الرقم ليس مستندًا إلى تقرير أو مصدر فعلي. وأحيانًا يرد بأن هذه البيانات ليست لديه لأن آخر تدريب له كان في التاريخ المعين، ويذكر التاريخ.
3. نقص المعلومات في البيانات
عندما يُطلب من النموذج التحدث عن موضوع لم يكن ممثلًا بشكل جيد في بيانات تدريبه، لا يتوقف عن الإجابة. بل يحاول "الارتجال" استنادًا إلى القليل المتاح، أو من خلال تخمين السياق العام.
⚠️المشكلة: هذا النوع من التخمين قد يبدو مُقنعًا على مستوى اللغة، لكنه في العمق مجرد تأليف. النموذج يملأ الفجوات بافتراضات مُستنتجة من أنماط لغوية وليس من حقائق.
💡مثال: إذا سألته عن تاريخ تأسيس جامعة صغيرة في أفريقيا لم تُذكر كثيرًا في النصوص، فقد يقول مثلًا "تأسست عام 1967"، رغم أن هذه المعلومة غير صحيحة.
4. الأسئلة الغامضة أو المفتوحة جدًا
عندما يكون السؤال غير دقيق أو مفتوحًا على احتمالات كثيرة، فإن النموذج يبدأ في "تخمين" ما يريد المستخدم، ويملأ الفجوات بما يراه أقرب منطقًا، لا بما هو مؤكد أو دقيق.
⚠️المشكلة: لأن النموذج لا يملك نية أو فهمًا حقيقيًا لسياق السؤال، فقد يقدم إجابة خيالية أو غير موجودة إذا اعتقد أنها "منطقية" لغويًا.
💡مثال: إذا طُرح عليه سؤال مثل، ما هي قوانين الروبوتات في السعودية؟، ولم يكن هناك قوانين فعلية بهذا الاسم، فقد يخترع واحدة مثل "قانون الروبوتات 2022" ويبدأ في وصفه.
5. الحدود التقنية للنموذج
كل نموذج لغوي لديه ما يسمى بـ"السعة السياقية" (Context Window)، وهي عدد الكلمات أو الرموز التي يستطيع تذكرها أو تحليلها في المحادثة الواحدة. إذا تجاوز النص هذا الحد، يبدأ النموذج في فقدان الانتباه للتفاصيل السابقة.
⚠️المشكلة: في المحادثات الطويلة أو النصوص المعقدة، قد ينسى النموذج تفاصيل مهمة أو يخلط بين مفاهيم، مما يؤدي إلى أخطاء واضحة أو تشويش في المعنى.
💡مثال: في حديث طويل عن السياسات الاقتصادية في دول الخليج، قد يخلط النموذج بين سياسة السعودية والإمارات، أو ينسب قرارًا إلى الدولة الخطأ.
6. النموذج لا "يفهم" الحقيقة
رغم الطابع "الذكي" للنموذج، إلا أنه لا يملك فهمًا فعليًا للحياة أو الواقع. هو يتعامل مع النصوص كأنماط إحصائية، ويتنبأ بالكلمة التالية دون أي إدراك للمعنى الحقيقي أو للعالم الخارجي.
⚠️المشكلة: هذا يؤدي إلى إنتاج جمل مقنعة على السطح، لكنها قد تكون خاطئة تمامًا لأن النموذج ببساطة لا يميّز بين ما هو صحيح وما هو غير صحيح.
💡مثال: قد يقول إن "توماس إديسون اخترع الإنترنت"، لأن هذه الشخصيات تظهر في نفس النصوص المتعلقة بالتكنولوجيا، رغم أن هذا خطأ فادح.
ما هي أنواع هلوسة الذكاء الاصطناعي؟
هناك 6 أنواع شائعة لهلوسة الذكاء الاصطناعي يجب أن تعرفها المؤسسات وقطاعات الأعمال المختلفة قبل التعامل مع أي نموذج ذكاء اصطناعي في عملها. وفيما يلي نشرح كل نوع بالتفصيل:
1. هلوسة واقعية (Factual Hallucination)
تحدث عندما يُقدم النموذج معلومات خاطئة ولكن بصيغة واثقة ومقنعة. المشكلة هنا أن النموذج لا يعرف ما هو صحيح أو خاطئ، بل يستند إلى الأنماط التي شاهدها أثناء التدريب.
لماذا تحدث؟
لأن النموذج لا يمتلك قاعدة بيانات موثقة، بل يعتمد على احتمالية الكلمات والجمل التي ظهرت في النصوص التي دُرّب عليها.
💡 مثال تطبيقي:
سؤال: هل توجد دراسة سعودية حول تأثير الذكاء الاصطناعي على التعليم؟
الجواب الهلوسي: "نعم، نُشرت دراسة في مجلة Saudi Journal of AI Education عام 2022 أثبتت أن استخدام الذكاء الاصطناعي رفع نتائج الطلاب بنسبة 35%."
الواقع: لا توجد مجلة بهذا الاسم ولا هذه الدراسة، والمعلومة ملفقة بالكامل رغم أنها تبدو موثوقة.
2. هلوسة المصدر (Citation Hallucination)
تظهر هذه الهلوسة عندما يختلق النموذج اسم كتاب، مجلة، دراسة أو جهة علمية لإسناد معلومة، ظنًا أن ذلك يُضفي على النص مصداقية. وغالبًا ما تكون هذه المصادر وهمية أو مركبة.
لماذا تحدث؟
النموذج يعرف أن "النصوص الموثوقة" تذكر مصادر، لذا يحاول تركيب مصدر بناءً على الشكل المتوقع، وليس بناءً على تحقق فعلي.
💡 مثال تطبيقي:
"أشارت دراسة في Harvard Journal of Medical AI إلى أن الذكاء الاصطناعي دقيق بنسبة 98% في تشخيص الأورام."
الواقع: لا توجد مجلة بهذا الاسم، ولم تصدر هذه الدراسة.
3. هلوسة منطقية (Logical Hallucination)
هنا لا تكون المشكلة في دقة المعلومات، بل في كيفية ربطها. النموذج يخلط بين الحقائق أو يبني استنتاجات غير منطقية رغم أن المعطيات صحيحة.
لماذا تحدث؟
لأن النموذج لا يفهم المنطق السببي، بل يُكوّن الجمل بناءً على احتمالية التسلسل اللغوي، وليس على قواعد المنطق العقلي.
💡 مثال توضيحي:
"أحمد أطول من خالد، وخالد أطول من سامي، إذًا سامي أطول من أحمد."
الواقع: الاستنتاج خاطئ منطقيًا، لكن الجملة تبدو لغويًا سليمة.
4. هلوسة لغوية (Linguistic Hallucination)
في هذا النوع، تكون الجمل سليمة من الناحية النحوية والإملائية، ولكنها تفتقر للمعنى، أو تحتوي على تركيب لغوي غريب أو إنشائي مفرط لا يخدم أي محتوى.
لماذا تحدث؟
النموذج يحاول إنتاج لغة فخمة أو "ذكية" لكنه لا يُقيّم مدى المعنى أو الفائدة من الجملة الناتجة.
💡 مثال توضيحي:
"الذكاء الاصطناعي ينبض في فضاء الخوارزميات الزمكانية للبيانات المتمركزة على محاور الإدراك الحاسوبي."
الواقع: الجملة بلا معنى حقيقي رغم أنها تبدو "مثقفة".
5. هلوسة وظيفية (Functional Hallucination)
تحدث عندما يكتب النموذج كود برمجي يبدو صحيحًا من الناحية اللغوية، لكنه لا يعمل تقنيًا. النموذج يعامل الكود كنص فقط، وليس كنظام منطقي له نتائج تشغيلية.
لماذا تحدث؟
النموذج لا يفهم قواعد التنفيذ البرمجي، بل فقط تركيب الجمل البرمجية على شكل أنماط نصية.
💡 مثال توضيحي:
يقوم النموذج بإنشاء دالة fetchUserInfoFromCloud() في جافا سكريبت، رغم أن هذه الدالة غير موجودة في أي مكتبة معروفة، ولا تعمل عند التنفيذ.
6. هلوسة ذاتية (Self-Contradictory Hallucination)
يحدث أن يناقض النموذج نفسه في نفس الرد أو الحوار. قد يبدأ بإعطاء معلومة، ثم يُنكرها لاحقًا دون وعي بذلك.
لماذا تحدث؟
النموذج لا يحتفظ دائمًا بسياق ثابت، خصوصًا في المحادثات الطويلة، أو عندما يُطلب منه إعادة صياغة أو الاستفاضة.
💡 مثال توضيحي:
"شركة هواوي لم تطور هواتف قابلة للطي."
ثم لاحقًا: "وقد أطلقت هواوي أول هاتف قابل للطي في عام 2020."
الواقع: النموذج وقع في تناقض واضح.
.webp)
7 مخاطر لهلوسة الذكاء الاصطناعي على الحكومات والشركات الكبيرة
مع تزايد اعتماد الحكومات والشركات الكبيرة على الذكاء الاصطناعي في اتخاذ القرارات، وتحليل البيانات، وإنتاج المحتوى، أصبحت هلوسة الذكاء الاصطناعي أحد التحديات الكبيرة التي يمكن أن تؤثر بشكل خطير على دقة وكفاءة العمليات. وفيما يلي أبرز مخاطرها بالتفصيل:
1. اتخاذ قرارات خاطئة مبنية على معلومات مغلوطة
النماذج اللغوية للذكاء الاصطناعي، مثل GPT، تُستخدم بشكل متزايد في تحليل البيانات وإعداد التقارير وصياغة الاستراتيجيات. لكن إذا كانت المخرجات تحتوي على هلوسات — مثل معلومات مختلقة أو غير دقيقة — فإن هذا قد يؤدي إلى اتخاذ قرارات خاطئة. مثلاً، في حال كانت الحكومة أو شركة كبيرة تعتمد على تقارير تحليلية غير دقيقة، قد يؤدي ذلك إلى استثمار غير مجدي أو تغييرات استراتيجية خاطئة بناءً على بيانات مغلوطة.
💡مثال: في حالة دراسة سوق جديدة، إذا اعتمد المسؤولون على تقرير ذكاء اصطناعي يحتوي على إحصائيات غير موجودة أو أرقام غير دقيقة، قد يتم تخصيص ميزانية ضخمة لمشروع فاشل.
2. تشويه السمعة والمعلومات الرسمية
عند تقديم بيانات مُختلقة أو معلومات غير دقيقة، يمكن أن يؤدي الذكاء الاصطناعي إلى تشويه سمعة الحكومة أو المؤسسة إذا تم نشر هذه المعلومات بشكل رسمي. هذه المشكلات يمكن أن تحدث بسهولة إذا كانت النماذج تُستخدم لإنشاء محتوى مثل تقارير إعلامية أو مواد تسويقية دون تحقق من صحة المصادر.
💡مثال: إذا تم نشر تقرير حكومي باستخدام بيانات غير موثوقة تم توليدها بواسطة الذكاء الاصطناعي، يمكن أن تُتهم الحكومة بالتضليل أو نشر معلومات خاطئة، مما قد يؤدي إلى تراجع في الثقة العامة.
3. المساس بالأمن السيبراني والتنظيمي
الذكاء الاصطناعي يُستخدم بشكل متزايد لتطوير الأنظمة الأمنية، لكن هلوسة الذكاء الاصطناعي في كتابة أو توليد الأكواد قد يؤدي إلى ثغرات أمنية حقيقية. إذا كانت الأنظمة تعتمد على مخرجات الذكاء الاصطناعي لتأمين البيانات أو تطوير أدوات حماية، فإن الخطأ في الكود قد يؤدي إلى اختراقات أو تسريب بيانات حساسة.
💡مثال: إذا تم استخدام نموذج ذكاء اصطناعي لتوليد نظام أمني لموقع حكومي، وقام النموذج بتوليد كود خاطئ أو غير متكامل، يمكن للمهاجمين استغلال هذه الثغرات للوصول إلى معلومات حساسة.
4. التأثير على الخطاب العام وصناعة السياسات
الذكاء الاصطناعي يُستخدم لإنشاء خطب، مقاطع فيديو، أو حتى مسودات قوانين. إذا اعتمدت الحكومات على نماذج الذكاء الاصطناعي في إعداد مشاريع القوانين أو الخطط الاستراتيجية دون التحقق الدقيق من دقة المعلومات، فإن ذلك قد يؤدي إلى وضع سياسات غير دقيقة أو مليئة بالأخطاء. الأمر الذي قد يؤثر على المواطنين وعلى صانعي السياسات بشكل كبير.
💡مثال: في حال طلبت حكومة ما من الذكاء الاصطناعي تقديم مسودة قانون جديد، فإن النموذج قد يُنتج مسودة تحتوي على أخطاء قانونية أو أرقام غير دقيقة، مما يعرض القانون للانتقاد أو الاستبدال لاحقًا.
5. تأثير سلبي على الابتكار والتطوير
عندما تعتمد الشركات الكبيرة على الذكاء الاصطناعي لتطوير منتجات جديدة أو تحسين العمليات، فإن أي خطأ في التنبؤات أو التصورات التي يقدمها الذكاء الاصطناعي قد يعرقل الابتكار. إذا كان النموذج يخطئ في تقدير احتياجات السوق أو يفترض فرضيات غير دقيقة، فإن ذلك قد يؤدي إلى تطوير منتجات غير ملائمة أو فشل في تلبية احتياجات العملاء.
💡مثال: إذا كانت شركة تكنولوجية تعتمد على الذكاء الاصطناعي لتطوير منتج جديد، وكان النموذج يخطئ في تقدير تفضيلات المستهلكين، فقد يؤدي ذلك إلى إطلاق منتج لا يحظى بإقبال كبير في السوق.
6. تكاليف عالية لتصحيح الأخطاء
عندما تحدث هلوسات الذكاء الاصطناعي وتؤدي إلى اتخاذ قرارات خاطئة أو نشر معلومات مغلوطة، فإن تكلفة تصحيح هذه الأخطاء قد تكون باهظة. يمكن أن تتطلب هذه التصحيحات وقتًا طويلًا، بالإضافة إلى استثمار الموارد الكبيرة لإعادة التحقق من المعلومات وتعديل السياسات أو المنتجات.
💡مثال: إذا قامت إحدى الشركات الكبرى بنشر تقرير مغلوط أو تقديم منتج بناءً على تقديرات خاطئة من الذكاء الاصطناعي، فإن التكاليف المترتبة على إصلاح السمعة أو سحب المنتجات من السوق قد تكون ضخمة.
7. تأثيرات قانونية وأخلاقية
الاعتماد على الذكاء الاصطناعي قد يؤدي إلى حدوث مشاكل قانونية أو أخلاقية إذا تم استخدامه في خلق معلومات مزيفة أو تحريف البيانات. يمكن أن يكون لذلك عواقب خطيرة من الناحية القانونية، حيث قد يتم رفع قضايا ضد الحكومة أو الشركات في حال تم استخدام الذكاء الاصطناعي لتوليد معلومات مضللة أو تحريف الحقائق.
💡مثال: في حالة استخدام الذكاء الاصطناعي لتوليد تقارير صحفية خاطئة، قد تتعرض الحكومة أو الشركة للمسائلة القانونية بسبب نشر أخبار كاذبة أو بيانات مشوهة.
ما هي طرق الوقاية من هلوسة الذكاء الاصطناعي؟
للوقاية من مخاطر هلوسة الذكاء الاصطناعي، يجب على الحكومات والشركات الكبرى اتباع مجموعة من السياسات والإجراءات لضمان دقة المعلومات وكفاءة استخدام هذه التقنيات. إليك أبرز الطرق التي يمكن اتخاذها لحماية الحكومات والشركات من مخاطر هلوسة الذكاء الاصطناعي:
1. التدقيق والتحقق المستمر من البيانات
أحد الطرق الأساسية للوقاية من هلوسة الذكاء الاصطناعي هو ضمان أن البيانات التي يتم استخدامها في التدريب والتحليل هي بيانات موثوقة وموثقة. يجب على الحكومات والشركات التأكد من أن نماذج الذكاء الاصطناعي تعتمد على مصادر بيانات صحيحة ومحدثة، كما يجب التحقق المستمر من صحة هذه البيانات.
💡الخطوة العملية: وضع نظام تدقيق داخلي أو خارجي للتحقق من دقة البيانات المدخلة في الأنظمة الذكية، وضمان تنوع مصادر البيانات لتجنب الانحياز.
2. التحقق البشري والمراجعة المتعددة
على الرغم من تقدم الذكاء الاصطناعي، إلا أن هناك حاجة ماسة للتحقق البشري عند التعامل مع مخرجاته، خاصة في الحالات التي تتعلق باتخاذ قرارات استراتيجية أو إعداد تقارير حساسة.
ينبغي أن يكون هناك دور رقابي من البشر لضمان صحة النتائج والتأكد من أن المخرجات لا تحتوي على هلوسة أو أخطاء.
💡الخطوة العملية: توظيف فرق من الخبراء لتحليل مخرجات الذكاء الاصطناعي ومراجعتها، خاصة في المجالات الحساسة مثل التقارير الحكومية أو القرارات التجارية الكبرى.
3. التدريب على نماذج متقدمة وموثوقة
من الضروري أن تقوم الحكومات والشركات بتدريب نماذج الذكاء الاصطناعي على مجموعات بيانات شاملة ومتنوعة تتسم بالدقة والموثوقية. يمكن تحسين النماذج عبر تقديم بيانات متنوعة وشاملة تجنبًا للهلوسة، مثل بيانات متنوعة ثقافيًا، جغرافيًا، وتقنيًا.
💡الخطوة العملية: التأكد من أن نماذج الذكاء الاصطناعي تشمل مجموعة واسعة من البيانات وتركز على جودة البيانات بدلًا من الكم.
4. التحديث الدوري للنماذج والبيانات
النماذج التي تعتمد على بيانات قديمة أو غير مُحدَّثة يمكن أن تنتج مخرجات غير دقيقة، مما يؤدي إلى هلوسة. لتجنب ذلك، من المهم تحديث نماذج الذكاء الاصطناعي بشكل دوري لتواكب أحدث المعلومات والاتجاهات في البيانات.
💡الخطوة العملية: وضع خطة لتحديث النماذج والبيانات بشكل مستمر لضمان أن تكون المخرجات قائمة على أحدث المعلومات المتاحة.
5. استخدام نماذج ذكاء اصطناعي متعددة للتحقق المتبادل
استخدام مجموعة من النماذج الذكية التي تعتمد على خوارزميات وتقنيات مختلفة يمكن أن يساعد في تقليل مخاطر هلوسة الذكاء الاصطناعي. من خلال مقارنة النتائج المستخلصة من نماذج متعددة، يمكن تحديد الاختلافات والتحقق من صحة البيانات قبل اتخاذ أي قرارات هامة.
💡الخطوة العملية: تطبيق استراتيجية "التحقق المتبادل" باستخدام نماذج متعددة، وذلك لتحقيق التوازن بين دقة البيانات وتعدد التحليلات.
6. تطوير آليات للكشف عن هلوسة الذكاء الاصطناعي
يجب أن تتوفر أدوات وآليات خاصة للكشف عن هلوسة الذكاء الاصطناعي بشكل تلقائي. يمكن أن تشمل هذه الأدوات أدوات للتحقق من مصادر البيانات، وتحليل النصوص والبيانات المستخلصة لتحديد ما إذا كانت تحتوي على معلومات غير موثوقة أو مختلقة.
💡الخطوة العملية: تطوير أدوات للكشف التلقائي عن هلوسة الذكاء الاصطناعي في المخرجات النصية أو البيانات، مثل أدوات تحقق المصادر والمحتوى.
7. تعليم وتدريب الموظفين على التعامل مع الذكاء الاصطناعي
من المهم أن تقوم الحكومات والشركات بتدريب موظفيها على استخدام الذكاء الاصطناعي بحذر وفهم كيفية التعامل مع مخرجاته. يجب أن يكون لدى الموظفين القدرة على تقييم المعلومات والتأكد من صحتها، وكذلك معرفة كيفية التصرف في حال اكتشافهم لهلوسة في البيانات.
💡الخطوة العملية: توفير برامج تدريبية متخصصة للموظفين لضمان الوعي الكامل بمخاطر الذكاء الاصطناعي وكيفية التعامل معها.
8. إعداد بروتوكولات للتعامل مع الأخطاء والهلوسة
يجب أن تكون هناك بروتوكولات واضحة ومحددة للتعامل مع حالات هلوسة الذكاء الاصطناعي، تشمل الإجراءات اللازمة لتصحيح الأخطاء والتأكد من أن هذه الأخطاء لا تؤثر على اتخاذ القرارات أو على العملية المؤسسية.
💡الخطوة العملية: وضع بروتوكولات للطوارئ تتضمن آلية لتصحيح الأخطاء التي تنجم عن مخرجات الذكاء الاصطناعي، وضمان اتخاذ الإجراءات التصحيحية في الوقت المناسب.
9. الشفافية في استخدام الذكاء الاصطناعي
من الضروري أن تكون الحكومات والشركات شفافة في استخدام تقنيات الذكاء الاصطناعي، مع توضيح كيفية استخدام هذه التقنيات والأدوات في صنع القرارات. الشفافية تساهم في بناء الثقة وتقليل المخاطر الناتجة عن استخدام نماذج قد تحتوي على هلوسات.
💡الخطوة العملية: نشر تقارير دورية عن كيفية استخدام الذكاء الاصطناعي في المؤسسة، والمخاطر المرتبطة به، وآليات التحقق المعتمدة.
10. مراقبة أثر الذكاء الاصطناعي على المدى الطويل
أخيرًا، يجب على الحكومات والشركات مراقبة تأثيرات الذكاء الاصطناعي بشكل دوري على المدى الطويل، وذلك لضمان أن الأنظمة المتبعة لا تتسبب في مشاكل غير متوقعة أو هلوسات في المستقبل. يمكن أن يتطلب ذلك تحديث الاستراتيجيات بشكل مستمر.
💡الخطوة العملية: إجراء تقييمات دورية للأثر طويل المدى لاستخدام الذكاء الاصطناعي في اتخاذ القرارات والتحليل داخل المنظمة.
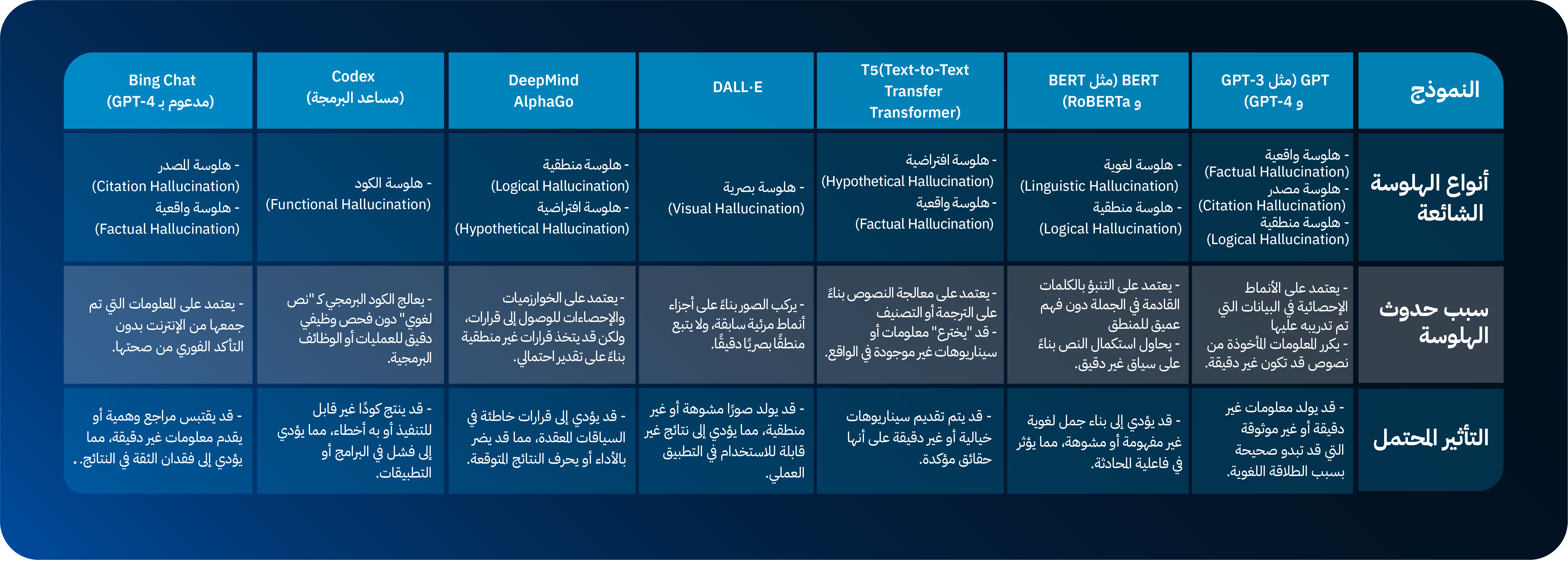
مقارنة بين نماذج الذكاء الاصطناعي من حيث الهلوسة
الخلاصة
في العالم العربي، تمثل هلوسة الذكاء الاصطناعي خطرًا حقيقيًا على الحكومات والشركات الكبرى، خاصة عند الاعتماد عليه في اتخاذ قرارات استراتيجية أو إنتاج محتوى رسمي. يمكن أن تؤدي الهلوسة إلى نشر معلومات غير دقيقة، أو تقديم بيانات مغلوطة في مجالات حساسة مثل السياسات العامة، الأمن السيبراني، أو التحليلات الاقتصادية، مما يُضعف الثقة في الذكاء الاصطناعي ويعرّض المؤسسات لأخطاء مُكلفة أو حتى لأزمات إعلامية وتشريعية.
للوقاية من هذه المخاطر، ينبغي على الجهات العربية تبني آليات تحقق صارمة قبل اعتماد أي مخرجات من النماذج الذكية، وتدريب فرق العمل على فهم حدود هذه التقنيات. كما يُستحسن الجمع بين الذكاء الاصطناعي والرقابة البشرية، وتطوير سياسات واضحة لاستخدامه في البيئات الحكومية والخاصة، مما يضمن الاستفادة منه بأمان وكفاءة دون الانجرار خلف أخطائه.
هل صادفت الحصول على إجابات غير منطقية من نموذج ذكاء اصطناعي؟ وكيف تعاملت معها؟ شاركنا في التعليقات.👇




%20(1).webp)


