
جدول المحتويات:
- تحدي التركيب اللغوي العربي في الذكاء الاصطناعي
- تحدي اللهجات العربية وتعدد السياقات
- تحديات الكتابة من اليمين إلى اليسار (RTL) في الذكاء الاصطناعي
- فجوة البيانات العربية وجودتها
- تحديات الفهم الدلالي والسياقي في النماذج الذكية
- تحديات التكامل ونشر النماذج العربية
- كيف تقدم وايدبوت حلولًا عملية لهذه التحديات؟
- الخلاصة: مستقبل اللغة العربية في عصر الذكاء الاصطناعي
====================================================================
تحديات اللغة العربية والذكاء الاصطناعي 2026: من التركيب اللغوي إلى اللهجات وRTL
التركيب اللغوي المعقد، تعدد اللهجات العربية، الكتابة من اليمين إلى اليسار (RTL - right to left)، نقص البيانات عالية الجودة، وصعوبة الفهم السياقي؛ تمثل هذه العوامل أبرز تحديات اللغة العربية والذكاء الاصطناعي بحلول عام 2026.
هذه التحديات لا تمثل عوائق تقنية فقط، بل أصبحت عوامل حاسمة قد تُحدد من ينجح ومن يتراجع في سباق التحول الرقمي في العالم العربي.
ففي الوقت الذي يشهد فيه الذكاء الاصطناعي تطورًا غير مسبوق، وتوسعًا هائلًا في استخدامه داخل الحكومات والشركات الكبرى، تبرز اللغة العربية كلغة «صعبة المراس»، تتطلب نماذج مُصممة خصيصًا، لا حلولًا عامة مستوردة.
في هذا المقال، نستعرض بشكل تحليلي ومتخصص أهم تحديات اللغة العربية والذكاء الاصطناعي في عام 2026، وتأثيرها المباشر على المؤسسات، ثم ننتقل إلى استعراض الحلول العملية التي تقدمها وايدبوت عبر نموذج «عقل» للذكاء الاصطناعي التوليدي.

إليك أبرز تحديات اللغة العربية والذكاء الاصطناعي في 2026:
1. تحدي التركيب اللغوي العربي في أنظمة الذكاء الاصطناعي
يُعد التركيب اللغوي العربي من أكثر الجوانب تعقيدًا في معالجة اللغة الطبيعية. فالكلمة العربية الواحدة قد تحتوي على جذر، ووزن، وسوابق، ولواحق، وضمائر متصلة، ما يجعل تحليلها آليًا مهمة عالية التعقيد.
فاللغة العربية تعتمد على الاشتقاق، حيث تُنتج الكلمة الواحدة من نظام الاشتقاق الثلاثي/رباعي آلاف المشتقات. مثال: جذر "كتب" يولّد (كاتب، مكتبة، كتابة، مكتوب) مع تغييرات صرفية دقيقة.
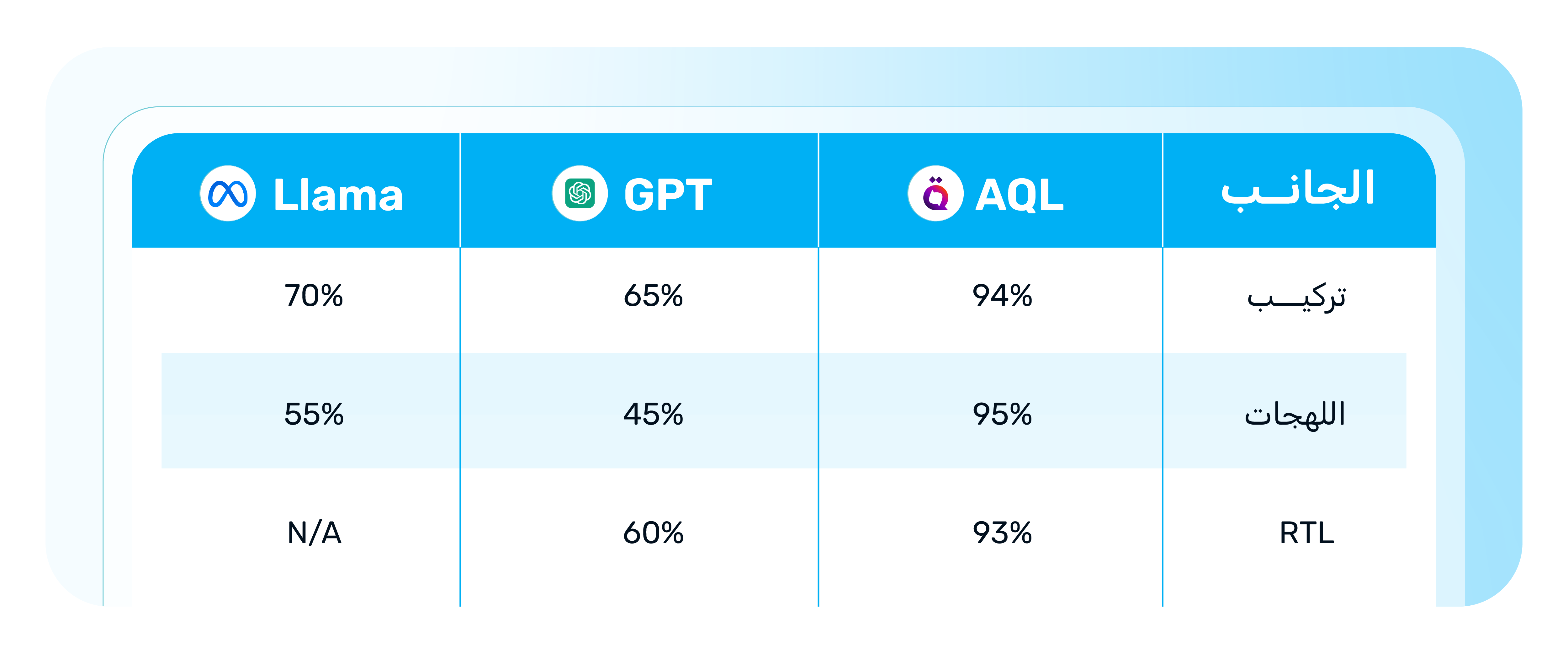
هذا التعقيد يؤدي إلى انخفاض دقة النماذج العالمية بنسبة تتراوح بين 25% و35% في مهام مثل:
- التعرف على الكيانات (NER)
- وسم أجزاء الكلام (POS Tagging)
خاصة عند التعامل مع الإعراب ومشتقات اللغة، كما أن غياب التشكيل في معظم النصوص الرقمية يزيد من حدة المشكلة، حيث تصبح الكلمة الواحدة قابلة لعدة تفسيرات، مما يؤثر مباشرة على دقة تصنيف النوايا، وتوليد النصوص.
2. تحدي اللهجات العربية وتعدد السياقات
تضم اللغة العربية ما يقارب 30 لهجة رئيسية، تختلف بنسبة تتراوح بين 60% و80% في النطق والمفردات.
ورغم تفوق نماذج عالمية من OpenAI مثل نموذج GPT في اللغة العربية الفصحى (بدقة تصل إلى 85%)، إلا أن أدائها ينخفض بشكل كبير عند التعامل مع اللهجات، ليصل في بعض الحالات إلى 45% فقط.
واليوم، أكثر من ثلثي المحتوى العربي الرقمي يُكتب باللهجات المحلية، لا بالفصحى.
وتختلف هذه اللهجات في:
- المفردات
- التراكيب النحوية
- الدلالات والسياقات الثقافية
وغالبًا ما تفشل النماذج العامة في فهم هذه اللهجات أو تخلط بينها، مما يؤدي إلى ردود غير دقيقة أو غير طبيعية، خاصة في تطبيقات المحادثة الآلية وخدمة العملاء.
💡 لذلك تقدّم وايدبوت STT/TTS من خلال نموذج عقل للذكاء الاصطناعي لدعم أكثر من 25 لهجة بالمنطقة العربية بدقة 95% WER، وتقليل وقت الانتظار بأكثر من 70% على مستوى مختلف القطاعات.
تعرف على المزيد من تقنيات ومنتجات وايدبوت
3. تحديات الكتابة من اليمين إلى اليسار (RTL)
لا تختلف اللغة العربية لغويًا فقط، بل تقنيًا أيضًا. فالكتابة من اليمين إلى اليسار (RTL) تمثل تحديًا حقيقيًا عند:
- دمج النصوص العربية مع الأرقام أو اللغات الأخرى
- تحليل البيانات النصية
- عرض المحتوى داخل الواجهات والتقارير
أي خلل في دعم RTL يؤدي إلى أخطاء في تقنيات OCR وTTS، ويؤثر بشكل مباشر على تجربة المستخدم ودقة التحليل، خصوصًا في التطبيقات الحكومية التي تعتمد على معالجة المستندات الرسمية وملفات PDF.
4. فجوة البيانات العربية وجودتها
رغم عدد المتحدثين بالعربية، لا تزال البيانات العربية المستخدمة في تدريب النماذج:
- أقل حجمًا مقارنة بالإنجليزية
- أقل تنوعًا من حيث اللهجات والمجالات
- متفاوتة الجودة

5. تحديات الفهم الدلالي والسياقي
تعتمد اللغة العربية بشكل كبير على السياق، والبلاغة، والتضمين، وهو ما يجعل مهام مثل تحليل المشاعر وفهم النية أكثر تعقيدًا، خاصة في النصوص القصيرة أو المكتوبة باللهجات المختلفة.
غياب الفهم العميق للسياق قد يؤدي إلى استنتاجات خاطئة أو قرارات غير دقيقة داخل الأنظمة الذكية، وهو ما يمثل خطرًا حقيقيًا في القطاعات الحساسة مثل الخدمات الحكومية والمالية.
6. تحديات التكامل ونشر النماذج العربية
بالنسبة للمؤسسات الحكومية والشركات الكبرى، لا يقتصر التحدي على دقة النموذج فقط، بل يمتد إلى:
- طريقة النشر (محلي، سحابي، أو هجين)
- الامتثال للمعايير واللوائح المحلية
- حماية البيانات الحساسة
وفي الوقت الحالي، كثير من المؤسسات ترفض النماذج المستضافة خارج حدودها الجغرافية لأسباب تتعلق بالخصوصية والأمن، مما يتطلب حلول نشر مرنة وآمنة.
كيف تقدم وايدبوت حلولًا عملية لهذه التحديات؟
تتعامل وايدبوت مع اللغة العربية والذكاء الاصطناعي باعتبارهما الأساس، لا الاستثناء.
ومن خلال نموذج عقل للذكاء الاصطناعي التوليدي - AQL Gen AI، تقدم حلولًا عملية تشمل:
- نماذج لغوية كبيرة (LLM) مُخصصة للعربية ولهجاتها
- دعم متقدم للهجات المحلية في الفهم والتوليد
- بنية تقنية مُصممة خصيصًا لدعم RTL
- نماذج قابلة للتخصيص حسب القطاع والمجال
- خيارات نشر محلية وسحابية وهجينة متوافقة مع المتطلبات الحكومية
في عام 2026، لم تعد اللغة العربية تحديًا هامشيًا في مسار تطور الذكاء الاصطناعي، بل أصبحت معيارًا حاسمًا لقياس مدى نضج النماذج الذكية وقدرتها على العمل في بيئات واقعية ومعقدة. فالفهم السطحي للعربية لم يعد كافيًا، في ظل متطلبات الحكومات والشركات التي تبحث عن دقة، وموثوقية، وامتثال، وتجربة مستخدم طبيعية تحاكي التواصل البشري الحقيقي.من هنا، تبرز وايدبوت عبر نموذج عقل - AQL Gen AI كنموذج عملي متقدم يبرهن أن التحديات اللغوية العربية -من التركيب الصرفي، وتعدد اللهجات، إلى متطلبات RTL والخصوصية- يمكن تحويلها إلى ميزة تنافسية حقيقية. ففهم العربية بعمق لم يعد عبئًا تقنيًا، بل فرصة استراتيجية لبناء حلول ذكاء اصطناعي أكثر قربًا من المستخدم، وأكثر توافقًا مع السياق الثقافي واللغوي للمنطقة.سواء كنت جهة حكومية تسعى إلى تحسين الخدمات الرقمية، أو شركة تطمح إلى أتمتة تواصلها مع العملاء، أو مطورًا يبحث عن نماذج عربية موثوقة، فإن الاستثمار في ذكاء اصطناعي مُصمم للعربية من الأساس هو الخطوة الأذكى نحو المستقبل.ابدأ اليوم في بناء حلول ذكية تتحدث العربية كما يفهمها البشر، واكتشف كيف يمكن لحلول وايدبوت أن تُحدث فرقًا حقيقيًا في أعمالك.احجز اجتماع مع فريق وايدبوت الآن.
====================================================================
Resources: (19 Sep, 2025),The Landscape of Arabic Large Language Models, Communications of the ACM. https://cacm.acm.org/arab-world-regional-special-section/the-landscape-of-arabic-large-language-models/
(3 Sep, 2025) The Arabic Gap in AI: Why Representation Matters Beyond English, Welodata.https://welodata.ai/2025/09/03/bridging-the-arabic-ai-gap/#:~:text=The%20Data%20Quality%20Challenge%20in,Tunisian%20Arabic
(15 June, 2025) Challenges of Arabic Language Processing in AI Systems, Academic research: Academia https://www.academia.edu/143448738/Challenges_of_Arabic_Language_Processing_in_AI_Systems
(4 June, 2025) الذكاء الاصطناعي واللغة العربية: تحديات وآفاق في ضوء الدراسات الحديثة, research gate
https://www.researchgate.net/publication/394170185_aldhka_alastnay_wallght_alrbyt_thdyat_wafaq_fy_dw_aldrasat_alhdytht
الأسئلة الشائعة حول تحديات اللغة العربية والذكاء الاصطناعي
ما هي أبرز تحديات اللغة العربية في الذكاء الاصطناعي في 2026؟
أبرز التحديات تشمل التركيب اللغوي العربي المعقد القائم على نظام الجذر والاشتقاق، تعدد اللهجات العربية بحوالي 30 لهجة رئيسية، صعوبات الكتابة من اليمين إلى اليسار (RTL)، فجوة البيانات العربية وجودتها، وضعف الفهم الدلالي والسياقي في النماذج العامة. هذه التحديات تجعل النماذج العالمية تفقد من 25% إلى 35% من دقتها عند التعامل مع النصوص العربية.
لماذا تنخفض دقة نماذج مثل GPT عند التعامل مع اللهجات العربية؟
رغم أن النماذج العالمية تحقق دقة تصل إلى 85% في اللغة العربية الفصحى، إلا أن أداءها ينخفض إلى 45% أو أقل عند التعامل مع اللهجات. السبب أن اللهجات تختلف بنسبة 60% إلى 80% في النطق والمفردات والتراكيب النحوية، وأكثر من ثلثي المحتوى العربي الرقمي مكتوب باللهجات المحلية لا بالفصحى.
ما هي تحديات الكتابة من اليمين إلى اليسار (RTL) في الذكاء الاصطناعي؟
تحديات RTL تظهر عند دمج النصوص العربية مع الأرقام أو لغات أخرى، وفي تحليل البيانات النصية، وعرض المحتوى داخل الواجهات والتقارير. أي خلل في دعم RTL يؤدي إلى أخطاء في تقنيات OCR و TTS، ويؤثر مباشرة على تجربة المستخدم، خصوصاً في التطبيقات الحكومية التي تعتمد على معالجة المستندات الرسمية وملفات PDF.
كيف يعالج نموذج عقل (AQL) من وايدبوت تحديات اللغة العربية؟
نموذج عقل من وايدبوت مصمم خصيصاً للعربية ولهجاتها، ويقدم حلولاً عملية تشمل نماذج لغوية كبيرة (LLM) متخصصة في العربية، دعم متقدم لأكثر من 25 لهجة محلية بدقة تصل إلى 95% WER، بنية تقنية مصممة لدعم RTL، نماذج قابلة للتخصيص حسب القطاع، وخيارات نشر محلية وسحابية وهجينة متوافقة مع المتطلبات الحكومية.
لماذا تحتاج المؤسسات الحكومية والشركات إلى نماذج عربية متخصصة؟
المؤسسات الحكومية والشركات تحتاج إلى دقة عالية، موثوقية، امتثال للوائح المحلية، وحماية البيانات الحساسة. كثير من المؤسسات ترفض النماذج المستضافة خارج حدودها الجغرافية لأسباب تتعلق بالخصوصية والأمن، ما يتطلب حلولاً مرنة وآمنة. ومع توقع تجاوز الإنفاق على الذكاء الاصطناعي في الخليج ومصر 10 مليارات دولار بحلول 2026، فإن النماذج العامة قد تؤدي إلى ضياع جزء كبير من هذا الإنفاق.
كيف تؤثر فجوة البيانات العربية على أداء نماذج الذكاء الاصطناعي؟
البيانات العربية المستخدمة في تدريب النماذج أقل حجماً مقارنة بالإنجليزية، وأقل تنوعاً من حيث اللهجات والمجالات، ومتفاوتة الجودة. هذه الفجوة تجعل النماذج العامة تفشل في فهم السياقات الثقافية واللغوية الدقيقة، وتؤدي إلى استنتاجات خاطئة في المهام التي تعتمد على الفهم العميق، مثل تحليل المشاعر وفهم النوايا في القطاعات الحساسة كالخدمات الحكومية والمالية.






.png)
